
Crawlability, Indexability and Snippet Eligibility in AI Search
Crawlability, Indexability and Snippet Eligibility in AI Search: the technical foundations that determine whether your content gets discovered, indexed, and selected for generative AI answers.
ARTIFICIAL INTELLIGENCE
Video Guru
6/29/20267 min read
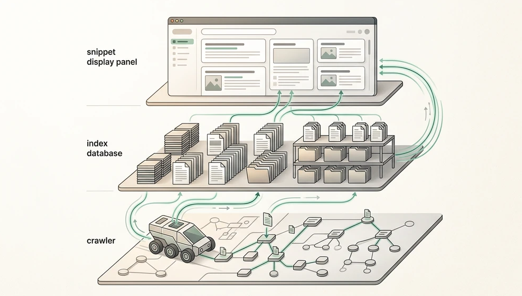
Direct answer: Crawlability, indexability, and snippet eligibility are the three technical prerequisites for AI search visibility. If a page cannot be crawled by search engine bots, stored in the index, or displayed as a snippet in results, it cannot be cited by AI systems such as Google AI Overviews or Bing Copilot — regardless of how well-written or authoritative the content may be. Each condition builds on the previous one: crawlability enables indexability, and indexability enables snippet eligibility. A failure at any stage breaks the chain to AI citation.
Crawlability: The First Gate
Crawlability refers to a search engine's ability to discover and retrieve a page's content. If a crawler cannot reach a URL, that URL effectively does not exist for AI systems. Googlebot, Bingbot, and the specialized crawlers that feed large language models all begin with the same fundamental operation: an HTTP request that must return a successful response.
robots.txt Management
The robots.txt file sits at the root of every domain and serves as the first instruction set crawlers consult. A single misconfigured Disallow directive can block entire directory trees from discovery. Common errors include blocking CSS and JavaScript files — which modern crawlers need to render pages accurately — and using overly broad wildcard patterns that inadvertently exclude valuable content.
Google confirmed in its AI features documentation that pages blocked by robots.txt may still appear in search results without a description, but they are unlikely to serve as sources for AI-generated overviews. The page must be crawlable to be fully processed and considered for citation.
Crawl Budget Optimization
Crawl budget represents the number of pages a search engine will crawl on a site within a given timeframe. Large websites with hundreds of thousands of URLs face particular pressure: low-priority or duplicate pages consume budget that should be directed toward high-value content. Methods to optimize crawl budget include eliminating redirect chains, consolidating near-duplicate pages, and using the nofollow attribute strategically on internal links to low-priority destinations.
Server Response Codes and JavaScript Rendering
A page returning 5xx server errors signals infrastructure instability and causes crawlers to deprioritize a site. Soft 404s — pages that return HTTP 200 but display "not found" content — confuse crawlers and waste crawl budget. JavaScript-rendered content presents an additional challenge: if critical content loads only after client-side execution, crawlers may fail to capture it unless the site properly implements dynamic rendering or server-side rendering. Google has improved its JavaScript handling significantly since 2023, but execution timeouts still occur on resource-heavy pages.
Site Speed as a Crawl Factor
Page load speed affects crawl rate directly. Slow-responding servers reduce the number of pages a crawler can process per session. Core Web Vitals metrics — Largest Contentful Paint, Interaction to Next Paint, and Cumulative Layout Shift — serve as proxy signals for crawl efficiency. Sites consistently exceeding 2.5 seconds for LCP often experience reduced crawl frequency.
Indexability: Storage and Retrieval
Crawlability grants access; indexability grants persistence. A page can be crawled successfully yet remain invisible to search systems if it fails to enter the index. Indexability encompasses the signals that tell search engines whether a page should be stored, how it should be ranked relative to duplicates, and how quickly it should appear in results.
noindex Directives and Their Consequences
The noindex directive — whether delivered via meta robots tag or X-Robots-Tag HTTP header — is the most definitive indexability control. A page carrying noindex will not appear in traditional search results and will not be cited by AI overviews. The directive is appropriate for internal search results pages, staging environments, and thin utility pages. However, accidental deployment of noindex on production content — often through a misplaced CMS setting or an inherited template — is one of the most damaging and under-detected technical SEO failures.
Canonical Tags and Duplicate Content
The canonical tag identifies the preferred version of a page when multiple URLs contain similar or identical content. E-commerce sites frequently generate duplicate URLs through filter parameters, session IDs, and tracking variables. Without proper canonicalization, search engines must guess which version to index and cite — and they may guess incorrectly. A self-referencing canonical on every preferred URL is the safest default practice.
XML Sitemaps and Index Discovery
XML sitemaps provide an explicit list of URLs that a site wants indexed. While sitemaps do not guarantee indexing, they significantly improve discovery efficiency — especially for deep pages with few internal links, new content on established domains, and large sites with complex navigation structures. Best practice includes maintaining separate sitemaps for different content types, keeping URLs below 50,000 per sitemap file, and updating the lastmod field when content substantively changes.
The IndexNow Protocol
IndexNow, supported by Bing and Yandex since 2021, allows sites to push notifications about content changes directly to participating search engines rather than waiting for crawlers to discover updates. Google's adoption remains partial as of early 2025, but Bing has integrated IndexNow deeply into its crawling infrastructure. Sites using IndexNow report faster indexation of new content, which directly improves the timeliness of AI citation eligibility.
Snippet Eligibility: The Display Layer
Snippet eligibility determines whether and how a page's content appears in search results. AI overviews and featured snippets draw directly from the indexed content of eligible pages. If a page blocks snippet display, it effectively removes itself from the pool of AI-citable sources.
Meta Descriptions and Structured Headings
Meta descriptions do not directly influence rankings, but they serve as the primary source for snippet text when no other content block is deemed more relevant. Well-crafted meta descriptions between 150 and 160 characters that accurately summarize page content increase the likelihood of selection for both traditional snippets and AI overview citations. Structured heading hierarchies — a single H1 followed by logical H2 and H3 divisions — help AI systems parse content structure and identify the most quotable passages.
Featured Snippet Optimization
Featured snippets occupy position zero and frequently supply the direct answers that AI overviews synthesize. Content formatted as concise definitions, ordered steps, comparison tables, and bullet lists captures featured snippet positions more reliably than narrative paragraphs. A definition paragraph of 40 to 60 words following a clear H2 question often wins the snippet for informational queries.
nosnippet and data-nosnippet Directives
The nosnippet meta robots tag prevents search engines from displaying any text snippet from a page in results. The data-nosnippet HTML attribute offers granular control, blocking specific HTML elements from appearing in snippets while leaving the rest of the page eligible. Pages using nosnippet are excluded from AI overview citation pools. This directive should be reserved for pages containing sensitive pricing, proprietary methodology, or content behind paywalls — not applied as a default precaution.
▶ Key Insight
Citation-ready insight: Technical SEO foundations function as non-negotiable prerequisites for AI citation visibility. A page must satisfy three sequential conditions — successful crawling, confirmed indexation, and snippet eligibility — before its content quality, authority signals, or semantic optimization can be evaluated by AI search systems. Content excellence without technical compliance produces zero citation outcomes.
12-Point Technical SEO Checklist for AI Visibility
Pre-Publication Technical Validation
· Verify the page is not blocked by robots.txt — test with Google's robots.txt Tester
· Confirm no noindex meta tag or X-Robots-Tag header is present on production URLs
· Implement self-referencing canonical tags on all preferred page versions
· Return HTTP 200 status codes for all indexable pages; fix 4xx and 5xx errors
· Ensure critical content renders without client-side JavaScript dependency
· Maintain server response times under 800ms for First Byte
· Submit updated XML sitemaps to Google Search Console and Bing Webmaster Tools
· Use IndexNow API for real-time indexation notifications on Bing
· Structure content with clear H1/H2/H3 hierarchy for passage extraction
· Write unique meta descriptions between 150-160 characters for every indexable page
· Audit for accidental nosnippet or data-nosnippet directives on citation-target pages
· Monitor crawl stats weekly in Search Console for anomaly detection
Common Technical Failures That Block AI Visibility
Real-world technical failures follow predictable patterns. Understanding these patterns accelerates diagnosis and prevents recurrence.
▶ Evidence
A mid-size SaaS company deployed a site-wide robots.txt block from their staging environment during a platform migration. All product pages disappeared from AI Overviews within 10 days. Resolution required removing the Disallow: / directive and resubmitting sitemaps. Full AI citation recovery took approximately six weeks — demonstrating that technical barriers create citation debt that persists even after fixes.
A publisher's WordPress SEO plugin update applied noindex to all category archive pages by default. Organic traffic declined 34% over three weeks before the configuration error was detected. AI overview citations for the publisher's domain dropped to zero for queries previously served by category page content. Reversing the setting and requesting reindexing through Search Console restored visibility within 14 days.
An e-commerce platform generated canonical tags pointing to parameterized filter URLs that returned soft 404s. Search engines interpreted the conflicting signals as low-quality content and reduced both ranking positions and snippet eligibility. Implementing self-referencing canonicals on all product pages and 301-redirecting orphaned filter URLs to parent categories resolved the issue within one crawl cycle.
Verification Methods and Monitoring
Technical compliance requires ongoing validation, not one-time setup. Three verification layers provide comprehensive coverage.
Google Search Console
Search Console offers the authoritative view of how Google processes a site. The Coverage report distinguishes between valid pages, excluded pages, and pages with errors. The Crawl Stats report under Settings reveals crawl frequency, response codes, and file types accessed. The URL Inspection tool allows real-time testing of individual pages for indexability status, canonical selection, and mobile usability. Any page targeting AI citation should show "URL is on Google" in the inspection tool.
The site: Operator
Searching site:example.com/page-url in Google provides a quick confirmation of index status. If the page does not appear, it is not indexed. If it appears without a description snippet, it may be blocked by robots.txt or carry a noindex directive that Google has not yet processed. This operator is useful for spot-checking but should not replace Search Console data for systematic monitoring.
Crawl Testing Tools
Third-party crawlers such as Screaming Frog, Sitebulb, and Lumar simulate search engine crawling at scale. These tools identify broken links, redirect chains, duplicate content, missing meta descriptions, and directive conflicts across thousands of URLs. Running a full-site crawl monthly catches configuration drift before it impacts indexability or snippet eligibility.
Frequently Asked Questions
Sources
1. Google. "AI Overview and AI Features in Search." Google Search Central. Available at: https://developers.google.com/search/docs/appearance/ai-features
2. Bing. "Introducing AI Performance in Bing Webmaster Tools — Public Preview." Bing Webmaster Blog, February 2026. Available at: https://blogs.bing.com/webmaster/February-2026/Introducing-AI-Performance-in-Bing-Webmaster-Tools-Public-Preview
Ready to audit your technical foundation? Review your technical SEO foundation for AI visibility with our specialized assessment.